High level
Distributed programming is the art of solving the same problem that you can solve on a single computer using multiple computers.
计算机两大任务
- 存储
- 计算
目标
- Scalability
- Performance (and latency)
- Short response time/low latency for a given piece of work
- High throughput (rate of processing work)
- Low utilization of computing resource(s)
- Availability (and fault tolerance)
- Availability = uptime / (uptime + downtime).
Abstractions and models
- System model (asynchronous / synchronous)
- Failure model (crash-fail, partitions, Byzantine)
- Consistency model (strong, eventual)
Design techniques: partition and replicate
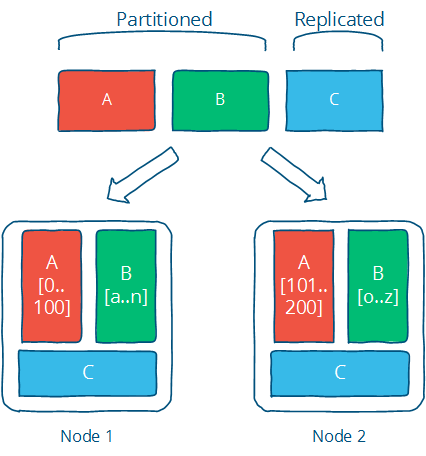
A system model
a set of assumptions about the environment and facilities on which a distributed system is implemented
Nodes in our system model
- the ability to execute a program
- the ability to store data into volatile memory (which can be lost upon failure) and into stable state (which can be read after a failure)
- a clock (which may or may not be assumed to be accurate)
FLP
there does not exist a (deterministic) algorithm for the consensus problem in an asynchronous system subject to failures, even if messages can never be lost, at most one process may fail, and it can only fail by crashing (stopping executing)
The CAP theorem
如果进程之间可能丢失某些消息,那么不可能在实现一致性存储的同时能响应所有的请求。
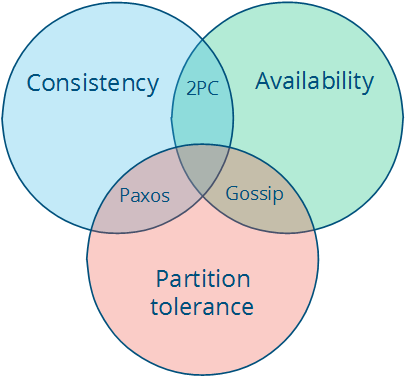
- Consistency: all nodes see the same data at the same time.
- Availability: node failures do not prevent survivors from continuing to operate.
- Partition tolerance: the system continues to operate despite message loss due to network and/or node failure
Strong consistency models (capable of maintaining a single copy)
- Linearizable consistency:Under linearizable consistency, all operations appear to have executed atomically in an order that is consistent with the global real-time ordering of operations. (Herlihy & Wing, 1991)
- Sequential consistency:Under sequential consistency, all operations appear to have executed atomically in some order that is consistent with the order seen at individual nodes and that is equal at all nodes. (Lamport, 1979)
Weak consistency models (not strong)
- Client-centric consistency models
- Causal consistency: strongest model available
- Eventual consistency models
Failure modes for distributed systems
- Byzantine or arbitrary failures
- Authentification detectable byzantine failures
- Performance failures
- Omission failures
- Crash failures
- Fail-stop failures